
dagster是 MDS 中推荐使用的调度组件。Dagster的官方文档已经挺完善挺人性化的了,但为了公司内推广,还是写一篇快速入门的文档吧。
除了文档,官方youtube也可以看看,比如 Dagster Day 2022 对dagster有整体的介绍。
准备工作
环境准备
首先,Dagster需要Python环境和pip:
- Python下载安装 :MacOS已自带。请确保 Python3.7及以上版本 。
- pip安装
使用pip安装:
pip install dagster
创建第一个项目
执行以下命令创建一个简单的dagster项目:
dagster project scaffold --name my-dagster-project
也可以使用官方例子创建项目,请参见: Create a New Project 。
随后执行以下命令安装依赖:
cd my-dagster-project
pip install -e ".[dev]"
最后执行下述命令启动一个dagster服务:
dagit
可以看到控制台打印出类似:
To persist information across sessions, set the environment variable DAGSTER_HOME to a directory to use.
0it [00:00, ?it/s]
0it [00:00, ?it/s]
2022-09-20 15:39:59 +0800 - dagit - INFO - Serving dagit on http://127.0.0.1:3000 in process 37014
即可在浏览器打开 http://127.0.0.1:3000 进入dagster页面。
快速理解dagster基本概念
命令
dagster提供了两个命令:
dagster: 核心CLI程序,可以用于执行单个job、查询asset、debug等,具体可通过dagster -h查询。dagit: dagster的UI服务,前面小节已经使用到了。
Asset
在传统的工作流/DAG调度工具里,我们面向执行的任务编写(代码)/(通过UI)编辑工作流,关注的是一个个任务的流转。
而这里定义的任务,对于数据处理而言,一般是读取一个数据源,经过处理后,写入另一个数据源。
我们知道一个任务处理了哪个数据源、输出了什么数据源,只能通过任务命名、或阅读任务的代码/注释/文档。
如果想知道这些用到的数据源之间的血缘关系,则需要调度工具支持+任务中声明输入输出的数据,或者在任务中调用第三方血缘关系管理的服务。
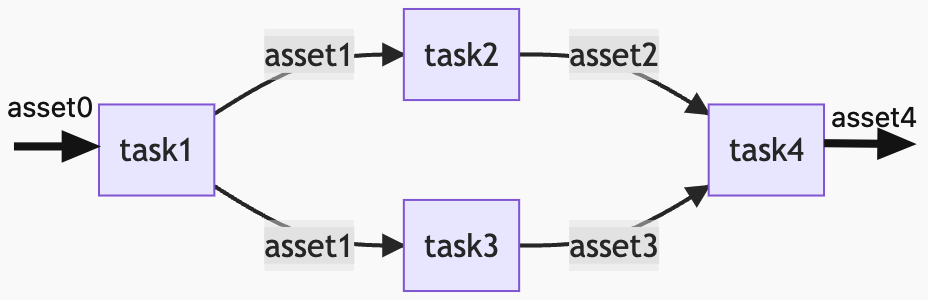
对于单纯的执行而言,这无疑是直观的。但如果从数仓建设的角度来看,这是很不人性化的:我们只能看到一步步做了什么,不能直观地看到数仓每一层的数据流转、依赖。
而 Dagster,提供了调度工作流的另一个视角: 数据资产视角 ,去审视数仓的数据流,从而声明式定义工作流。
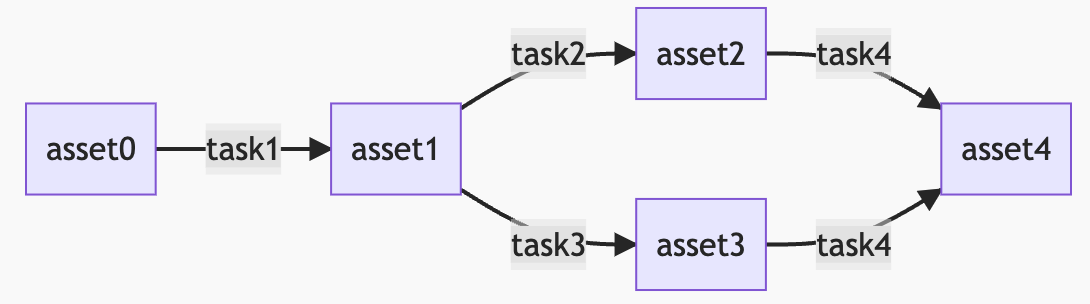
也就是说,在dagster里面,不再关注需要写什么任务,而是捋清到底有哪些数据资产,以及这些数据资产之间的关系。
然后在代码里声明:
- 数据资产:
@asset注解 - 这个数据资产依赖什么上游的数据资产:
@asset注解的ins或non_argument_deps属性 - 如何利用上游的数据资产产生当前数据资产:在
@asset声明的方法里通过py代码实现,比如依赖的DataFrame,在方法代码里用DataFrame API,编写业务逻辑,定义return 一个新的DataFrame
就可以了。
当你把数据资产都定义完,可以通过 define_asset_job 方法,将选定的数据资产,按依赖关系自动构建出DAG工作流(dagster称之为 job),然后就可以执行了。
关于 asset 的定义和使用更多信息,请参考官方文档:
- A First Asset
- Building Graphs of Assets
- Assets without Arguments and Return Values
- Testing Assets
- Software-Defined Assets
- Asset Materializations
- Asset Observations
- Multi-Assets
等。
说到这里,好像缺了什么?
DataFrame是定义完了,DataFrame保存到哪里?又是从哪里读的?
IO Manager
Asset只定义了数据资产的来源依赖与自身定义,关注的是数据的业务逻辑。
在传统的ETL工具或工作流工具里,数据的读写和处理逻辑是在同一个任务/工作流里定义的,而在Dagster中,数据的读写和处理逻辑是解耦的,处理逻辑在Asset定义了,而读写在 IO Manager 中定义。
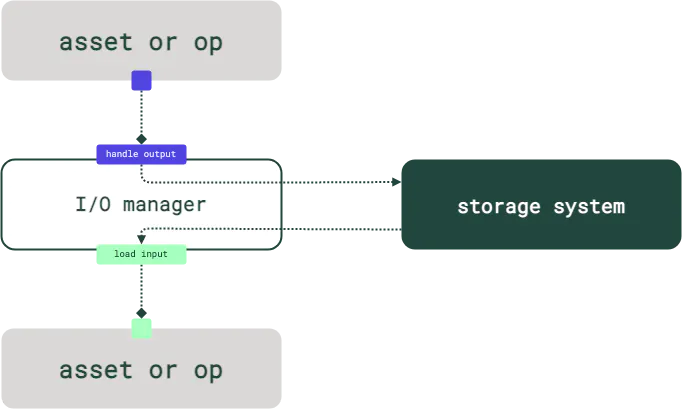
IO Manager有一些官方的实现,也可以自己实现。
具体来说是继承 dagster.IOManager,实现 handle_output(数据输出) 和 load_input(数据读取) 方法。
而每个Asset使用哪个IO Manager,则是在 @asset 注解的 io_manager_key 属性中设置,如:
class MyIOManager(IOManager):
def handle_output(self, context, obj):
pass
def load_input(self, context):
pass
@io_manager
def my_io_manager(init_context):
return MyIOManager()
@asset(io_manager_key="my_io_manager")
def my_op():
pass
具体请参见官方文档:
Op && Graph && Job
概念简介
Op(不是那个OP)是dagster最基础的计算单元,包括asset物化的时候,dagster也是包装成op进行执行的。
Op也定义了(一个或多个)输入和输出,也可通过IO Manager做存储管理,也可以使用job级别的 resource 定义。
还可以通过 @op 注解的 config_schema 定义执行时需要的op_config配置。
关于 Op 的文档:
- Writing, Executing a Single-Op Job
- Connecting Ops In Jobs
- Testing Ops and Jobs
- Ops
- Op Events and Exceptions
- Op Hooks
- Op Retries
Graph 可以将多个op或Graph组成DAG————“或Graph”,也就是说支持graph的嵌套。
graph的定义是通过python代码的入参依赖构建的,如官方的例子:
from dagster import graph, op
@op
def return_one(context) -> int:
return 1
@op
def add_one(context, number: int) -> int:
return number + 1
@graph
def linear():
add_one(add_one(add_one(return_one())))
关于 Graph 的文档:
Job 是Dagster的执行和监控单元,Job由Graph或Op(通过Python代码)连接而成。类比到传统调度服务,就是整个工作流了。
Job的定义方式与Graph类似,也是在Python代码中通过入参或注解实现依赖。
关于 Job 的文档:
几者转换 & 常用方法
其实也不是互相转换,主要是转成Job的。我们在代码里定义了asset、op、graph这些,是可以直接定义为一个job的。具体:
dagster.load_assets_from_modules:可以从指定的Python module中加载所有定义的asset,可以简化 repository 的配置。类似的还有load_assets_from_current_module、load_assets_from_package_module、load_assets_from_package_name等方法。dagster.define_asset_job: 可以将一系列的asset的物化动作作为一个job,可以通过selection属性选择所需的asset。dagster.GraphDefinition.to_job:可以将Graph定义(用Graph的方法名调用)转换为一个Jobdagster_dbt.load_assets_from_dbt_project:从dbt项目的模型定义加载asset,需要依赖dagster-dbtdagster_dbt.dbt_run_op:利用resource里面定义的dbt资源,产生一个dbt run的op。
Schedule & Sensor
image.png 是定时执行Job,可以简单地配置每小时、每天、每周等,也可以通过cron表达式配置。详见 Schedules。需要注意的是时区的配置,通过 ScheduleDefinition 的 execution_timezone 属性配置;以及可以通过 environment_vars 属性定义执行Job时的环境变量。
Sensor 定义在Job运行结束或asset物化结束后的操作,可以根据执行结果做任何自定义的操作,包括但不限于:
- 发送企业微信Bot消息通知
- 获取物化结果的OSS下载地址,发送邮件给客户
- 清理过时的分区数据
- ………………
详见 Sensors。
Schedule和Sensor的运行都需要 dagster-daemon 进程。
在k8s中,dagster-daemon可以与dagit分别做成一个pod里的两个容器。
Repository & Workspace
Repository 包含一个项目的所有 Asset、Op、Graph、Job、Schedule、Sensor 等资源。dagster UI左侧栏同一时间只显示一个Repository。通过 @repository 注解定义。
而 Workspace 是Dagit实例级别的工作区,可以包含多个Repository。通过 workspace.yaml 文件配置、里面从哪里加载Repository定义。
可以指定Python文件、Python的package、或gRpc服务(可通过 dagster 命令启动gRpc服务)。详见 Workspace。
dagster实例
在环境变量 DAGSTER_HOME 配置的目录下的 dagster.yaml 文件进行配置,该文件定义了Dagit实例的一些存储位置、日志等等配置。
详见 Dagster Instance。